feat(platform): improve invited user admin workflows#12471
feat(platform): improve invited user admin workflows#12471
Conversation
|
Note Reviews pausedIt looks like this branch is under active development. To avoid overwhelming you with review comments due to an influx of new commits, CodeRabbit has automatically paused this review. You can configure this behavior by changing the Use the following commands to manage reviews:
Use the checkboxes below for quick actions:
WalkthroughAdded server-side search and pagination for invited users; expanded bulk-invite to a two-phase validate+batch-create flow with higher row limit (5000) and duplicate pre-checks; introduced concurrency and rate-limiting for tally seed extraction with retry/timeout handling and a new TallyExtractionTimeoutError; corresponding frontend paging/search UI changes. Changes
Sequence Diagram(s)sequenceDiagram
participant UI as Admin UI
participant API as Admin API
participant InvitedService as InvitedUser Service
participant Parser as File Parser
participant Validator as Validator/Deduper
participant BatchCreator as Batch Creator
participant DB as Database
participant Tally as Tally/LLM
rect rgba(200,230,201,0.5)
UI->>API: upload bulk-invite file (with page/search)
API->>InvitedService: submit file for processing
end
InvitedService->>Parser: parse CSV/TXT -> rows
Parser->>Validator: validate rows serially (dedupe, normalize)
Validator->>InvitedService: return validated_rows
InvitedService->>BatchCreator: chunk validated_rows -> create tasks
BatchCreator->>DB: batch create invites (parallel via asyncio.gather)
DB-->>BatchCreator: per-row responses (created / precondition / error)
BatchCreator->>InvitedService: aggregate CREATED/SKIPPED/ERROR
InvitedService->>Tally: async enqueue/compute tally seed (rate-limited + semaphore)
Tally->>InvitedService: tally result or TallyExtractionTimeoutError
InvitedService->>API: return aggregated results and statuses
API->>UI: respond with created/skipped/errors and pagination
Estimated code review effort🎯 4 (Complex) | ⏱️ ~45 minutes Possibly related PRs
Suggested labels
Suggested reviewers
Poem
🚥 Pre-merge checks | ✅ 2 | ❌ 1❌ Failed checks (1 warning)
✅ Passed checks (2 passed)
✏️ Tip: You can configure your own custom pre-merge checks in the settings. ✨ Finishing Touches📝 Generate docstrings
🧪 Generate unit tests (beta)
📝 Coding Plan
Thanks for using CodeRabbit! It's free for OSS, and your support helps us grow. If you like it, consider giving us a shout-out. Comment |
🔍 PR Overlap DetectionThis check compares your PR against all other open PRs targeting the same branch to detect potential merge conflicts early. 🔴 Merge Conflicts DetectedThe following PRs have been tested and will have merge conflicts if merged after this PR. Consider coordinating with the authors.
Summary: 1 conflict(s), 0 medium risk, 0 low risk (out of 1 PRs with file overlap) Auto-generated on push. Ignores: |
There was a problem hiding this comment.
🧹 Nitpick comments (1)
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx (1)
57-57: Clarify or enforce the 1 MB limit in the UI flowLine 57 states a hard limit, but the current submit path does not pre-validate file size client-side. Consider either (a) adding a client-side
file.sizecheck before submit, or (b) adjusting copy to “Server limit: 1 MB” to avoid misleading UX on rejected uploads.🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/frontend/src/app/`(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx at line 57, The UI currently states "UTF-8 encoded, max 1 MB file size." but the submit flow in BulkInviteForm does not pre-validate file size; add a client-side file.size check in the file input handler or submit handler (e.g., onFileChange or handleSubmit in BulkInviteForm) to reject files > 1_048_576 bytes and show a user-facing error before sending to the server, or alternatively change the copy to "Server limit: 1 MB" to make the restriction declarative; update the component’s validation logic (and any error state like setError or validationMessage used by BulkInviteForm) so the UI prevents submission when the file is too large.
🤖 Prompt for all review comments with AI agents
Verify each finding against the current code and only fix it if needed.
Nitpick comments:
In
`@autogpt_platform/frontend/src/app/`(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx:
- Line 57: The UI currently states "UTF-8 encoded, max 1 MB file size." but the
submit flow in BulkInviteForm does not pre-validate file size; add a client-side
file.size check in the file input handler or submit handler (e.g., onFileChange
or handleSubmit in BulkInviteForm) to reject files > 1_048_576 bytes and show a
user-facing error before sending to the server, or alternatively change the copy
to "Server limit: 1 MB" to make the restriction declarative; update the
component’s validation logic (and any error state like setError or
validationMessage used by BulkInviteForm) so the UI prevents submission when the
file is too large.
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: 6ec21bef-f095-47d3-8810-70af270dc3ef
📒 Files selected for processing (2)
autogpt_platform/backend/backend/data/invited_user.pyautogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
💤 Files with no reviewable changes (1)
- autogpt_platform/backend/backend/data/invited_user.py
📜 Review details
⏰ Context from checks skipped due to timeout of 90000ms. You can increase the timeout in your CodeRabbit configuration to a maximum of 15 minutes (900000ms). (12)
- GitHub Check: integration_test
- GitHub Check: check API types
- GitHub Check: Seer Code Review
- GitHub Check: test (3.12)
- GitHub Check: test (3.11)
- GitHub Check: test (3.13)
- GitHub Check: type-check (3.12)
- GitHub Check: type-check (3.13)
- GitHub Check: type-check (3.11)
- GitHub Check: end-to-end tests
- GitHub Check: Analyze (python)
- GitHub Check: Check PR Status
🧰 Additional context used
📓 Path-based instructions (12)
autogpt_platform/frontend/**/*.{ts,tsx,js,jsx}
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/frontend/**/*.{ts,tsx,js,jsx}: Use Node.js 21+ with pnpm package manager for frontend development
Always run 'pnpm format' for formatting and linting code in frontend development
autogpt_platform/frontend/**/*.{ts,tsx,js,jsx}: Runpnpm formatto auto-fix formatting issues before completing work
Runpnpm lintto check for lint errors and fix any that appear before completing work
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/**/*.{tsx,ts}
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/frontend/**/*.{tsx,ts}: Use function declarations for components and handlers (not arrow functions) in React components
Only use arrow functions for small inline lambdas (map, filter, etc.) in React components
Use PascalCase for component names and camelCase with 'use' prefix for hook names in React
Use Tailwind CSS utilities only for styling in frontend components
Use design system components from 'src/components/' (atoms, molecules, organisms) in frontend development
Never use 'src/components/legacy/' in frontend code
Only use Phosphor Icons (@phosphor-icons/react) for icons in frontend components
Use generated API hooks from '@/app/api/generated/endpoints/' instead of deprecated 'BackendAPI' or 'src/lib/autogpt-server-api/'
Use React Query for server state (via generated hooks) in frontend development
Default to client components ('use client') in Next.js; only use server components for SEO or extreme TTFB needs
Use '' component for rendering errors in frontend UI; use toast notifications for mutation errors; use 'Sentry.captureException()' for manual exceptions
Separate render logic from data/behavior in React components; keep comments minimal (code should be self-documenting)
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/**/*.{ts,tsx}
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/frontend/**/*.{ts,tsx}: No barrel files or 'index.ts' re-exports in frontend code
Regenerate API hooks with 'pnpm generate:api' after backend OpenAPI spec changes in frontend developmentRun
pnpm typesto check for type errors and fix any that appear before completing work
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/**/*.{js,jsx,ts,tsx}
📄 CodeRabbit inference engine (AGENTS.md)
autogpt_platform/frontend/**/*.{js,jsx,ts,tsx}: Format frontend code usingpnpm format
Never use components fromsrc/components/__legacy__/*
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/src/**/*.{ts,tsx}
📄 CodeRabbit inference engine (AGENTS.md)
autogpt_platform/frontend/src/**/*.{ts,tsx}: Structure components asComponentName/ComponentName.tsx+useComponentName.ts+helpers.tsand use design system components fromsrc/components/(atoms, molecules, organisms)
Use generated API hooks from@/app/api/__generated__/endpoints/with patternuse{Method}{Version}{OperationName}and regenerate withpnpm generate:api
Use function declarations (not arrow functions) for components and handlers
Separate render logic from business logic with component.tsx + useComponent.ts + helpers.ts structure
Colocate state when possible, avoid creating large components, use sub-components in local/componentsfolder
Avoid large hooks, abstract logic intohelpers.tsfiles when sensible
Use arrow functions only for callbacks, not for component declarations
Avoid comments at all times unless the code is very complex
Do not useuseCallbackoruseMemounless asked to optimize a given function
autogpt_platform/frontend/src/**/*.{ts,tsx}: Use function declarations (not arrow functions) for components and handlers
Use type-safe generated API hooks via Orval + React Query for data fetching
Use React Query for server state management and co-locate UI state in components/hooks
Separate render logic (.tsx) from business logic (use*.tshooks)
Use only shadcn/ui (Radix UI primitives) with Tailwind CSS for UI components
Use Phosphor Icons only for all icon implementations
Use ErrorCard component for render errors, toast for mutations, and Sentry for exceptions
Use design system components fromsrc/components/(atoms, molecules, organisms)
Never usesrc/components/__legacy__/*components
Use generated API hooks from@/app/api/__generated__/endpoints/with patternuse{Method}{Version}{OperationName}
Use Tailwind CSS only for styling with design tokens
Do not useuseCallbackoruseMemounless asked to optimize a specific function
Never type withanyunless a variable/attribute can actually be of any type
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/**/*.{js,jsx,ts,tsx,css}
📄 CodeRabbit inference engine (AGENTS.md)
Use Tailwind CSS only for styling, use design tokens, and use Phosphor Icons only
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/src/**/*.tsx
📄 CodeRabbit inference engine (AGENTS.md)
Component props should be
interface Props { ... }(not exported) unless the interface needs to be used outside the componentUse
type Props = { ... }(not exported) for component props unless used outside the component
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/**/*.{ts,tsx}
📄 CodeRabbit inference engine (AGENTS.md)
Never type with
any, if no types available useunknown
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/src/app/(platform)/**/*.tsx
📄 CodeRabbit inference engine (AGENTS.md)
If adding protected frontend routes, update
frontend/lib/supabase/middleware.ts
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/src/**/*.{ts,tsx,js,jsx}
📄 CodeRabbit inference engine (autogpt_platform/frontend/CLAUDE.md)
Fully capitalize acronyms in symbols, e.g.
graphID,useBackendAPI
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/src/**/components/**/*.{ts,tsx}
📄 CodeRabbit inference engine (autogpt_platform/frontend/CLAUDE.md)
Put sub-components in a local
components/folder within the feature directory
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
autogpt_platform/frontend/src/**/[A-Z]*/**/*.{ts,tsx}
📄 CodeRabbit inference engine (autogpt_platform/frontend/CLAUDE.md)
Structure components as ComponentName/ComponentName.tsx + useComponentName.ts + helpers.ts
Files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
🧠 Learnings (2)
📓 Common learnings
Learnt from: Swiftyos
Repo: Significant-Gravitas/AutoGPT PR: 12347
File: autogpt_platform/backend/backend/data/invited_user.py:193-193
Timestamp: 2026-03-10T11:22:18.867Z
Learning: In Significant-Gravitas/AutoGPT, the admin data-layer functions in `autogpt_platform/backend/backend/data/invited_user.py` (`list_invited_users`, `create_invited_user`, `revoke_invited_user`, `retry_invited_user_tally`, `bulk_create_invited_users_from_file`) intentionally omit an acting-user/admin ID parameter. Authorization for these functions is enforced entirely at the FastAPI router layer via `Security(requires_admin_user)` in `user_admin_routes.py`. Do not flag the absence of a user_id/actor_id parameter in these functions as a missing data-access guardrail violation.
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12284
File: autogpt_platform/frontend/src/app/api/openapi.json:11897-11900
Timestamp: 2026-03-04T23:58:18.476Z
Learning: Repo: Significant-Gravitas/AutoGPT — PR `#12284`
Backend/frontend OpenAPI codegen convention: In backend/api/features/store/model.py, the StoreSubmission and StoreSubmissionAdminView models define submitted_at: datetime | None, changes_summary: str | None, and instructions: str | None with no default. This is intentional to produce “required but nullable” fields in OpenAPI (properties appear in required[] and use anyOf [type, null]). This matches Prisma’s submittedAt DateTime? and changesSummary String?. Do not flag this as a required/nullable mismatch.
📚 Learning: 2026-02-27T10:45:49.499Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12213
File: autogpt_platform/frontend/src/app/(platform)/copilot/tools/RunMCPTool/helpers.tsx:23-24
Timestamp: 2026-02-27T10:45:49.499Z
Learning: Prefer using generated OpenAPI types from '@/app/api/__generated__/' for payloads defined in openapi.json (e.g., MCPToolsDiscoveredResponse, MCPToolOutputResponse). Use inline TypeScript interfaces only for payloads that are SSE-stream-only and not exposed via OpenAPI. Apply this pattern to frontend tool components (e.g., RunMCPTool) and related areas where similar SSE/openapi-discrepancies occur; avoid re-implementing types when a generated type is available.
Applied to files:
autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
Removing the limit without batching allowed unbounded sequential DB writes and asyncio tasks per request. Raise the cap from 500 → 5000 to support larger uploads while avoiding connection pool exhaustion. Update frontend helper text to reflect the new 5 000-row limit.
Replace the hard row limit with a two-pass approach: 1. Validate and deduplicate emails serially (cheap). 2. Call create_invited_user in concurrent batches of 500 via asyncio.gather, bounding DB load while allowing unlimited rows within the 1 MB file-size constraint.
There was a problem hiding this comment.
Caution
Some comments are outside the diff and can’t be posted inline due to platform limitations.
⚠️ Outside diff range comments (1)
autogpt_platform/backend/backend/data/invited_user.py (1)
405-490:⚠️ Potential issue | 🟡 MinorPreserve input row order in
BulkInvitedUsersResult.results.Current two-pass appends can reorder rows (e.g., first-pass errors/skips are appended before valid-row outcomes). This can confuse consumers that render results in list order. Emit results in original parsed row order.
💡 Suggested fix (keep deterministic row order)
@@ - results: list[BulkInvitedUserRowResult] = [] + row_results: dict[int, BulkInvitedUserRowResult] = {} @@ - results.append( - BulkInvitedUserRowResult( - row_number=row.row_number, - email=row.email or None, - name=row_name, - status="ERROR", - message="Invalid email address", - ) - ) + row_results[row.row_number] = BulkInvitedUserRowResult( + row_number=row.row_number, + email=row.email or None, + name=row_name, + status="ERROR", + message="Invalid email address", + ) continue @@ - results.append( - BulkInvitedUserRowResult( - row_number=row.row_number, - email=normalized_email, - name=row_name, - status="SKIPPED", - message="Duplicate email in upload file", - ) - ) + row_results[row.row_number] = BulkInvitedUserRowResult( + row_number=row.row_number, + email=normalized_email, + name=row_name, + status="SKIPPED", + message="Duplicate email in upload file", + ) continue @@ - results.append( - BulkInvitedUserRowResult( - row_number=row.row_number, - email=normalized_email, - name=row_name, - status="SKIPPED", - message=str(outcome), - ) - ) + row_results[row.row_number] = BulkInvitedUserRowResult( + row_number=row.row_number, + email=normalized_email, + name=row_name, + status="SKIPPED", + message=str(outcome), + ) @@ - results.append( - BulkInvitedUserRowResult( - row_number=row.row_number, - email=normalized_email, - name=row_name, - status="ERROR", - message="Unexpected error creating invite", - ) - ) + row_results[row.row_number] = BulkInvitedUserRowResult( + row_number=row.row_number, + email=normalized_email, + name=row_name, + status="ERROR", + message="Unexpected error creating invite", + ) @@ - results.append( - BulkInvitedUserRowResult( - row_number=row.row_number, - email=normalized_email, - name=row_name, - status="CREATED", - message="Invite created", - invited_user=outcome, - ) - ) + row_results[row.row_number] = BulkInvitedUserRowResult( + row_number=row.row_number, + email=normalized_email, + name=row_name, + status="CREATED", + message="Invite created", + invited_user=outcome, + ) + ordered_results = [row_results[row.row_number] for row in parsed_rows] return BulkInvitedUsersResult( created_count=created_count, skipped_count=skipped_count, error_count=error_count, - results=results, + results=ordered_results, )🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/data/invited_user.py` around lines 405 - 490, Validation and creation currently append to results in two passes which can reorder rows; instead, allocate a results_by_row_number dict keyed by row.row_number and populate it during the first pass (set entries for invalid emails and duplicate skips and increment error_count/skipped_count) and during the second pass (set entries for PreconditionFailed/skipped, unexpected errors, and successful creates and update skipped_count/error_count/created_count accordingly). After both passes, rebuild BulkInvitedUsersResult.results by iterating the original parsed_rows in order and collecting results_by_row_number[row.row_number] so the final results list preserves the input row order; use the same types (BulkInvitedUserRowResult) and the existing symbols (parsed_rows, valid_rows, _BULK_INVITE_BATCH_SIZE, create_invited_user, mask_email) when implementing.
🧹 Nitpick comments (1)
autogpt_platform/backend/backend/data/invited_user.py (1)
48-48: Consider making_BULK_INVITE_BATCH_SIZEenvironment/config tunable.A fixed value of 500 may be too high/low depending on DB pool sizing per deployment. Making this configurable would reduce operational retuning via code changes.
🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/data/invited_user.py` at line 48, The hardcoded _BULK_INVITE_BATCH_SIZE should be made configurable by reading from an environment/config variable (e.g., os.getenv("BULK_INVITE_BATCH_SIZE")) with a fallback default of 500; locate the _BULK_INVITE_BATCH_SIZE constant in invited_user.py and replace its literal with code that reads the env var, casts to int, validates/clamps to a sensible >0 value, and uses the default if parsing fails, and update any related tests or docs to note the new BULK_INVITE_BATCH_SIZE config option.
🤖 Prompt for all review comments with AI agents
Verify each finding against the current code and only fix it if needed.
Outside diff comments:
In `@autogpt_platform/backend/backend/data/invited_user.py`:
- Around line 405-490: Validation and creation currently append to results in
two passes which can reorder rows; instead, allocate a results_by_row_number
dict keyed by row.row_number and populate it during the first pass (set entries
for invalid emails and duplicate skips and increment error_count/skipped_count)
and during the second pass (set entries for PreconditionFailed/skipped,
unexpected errors, and successful creates and update
skipped_count/error_count/created_count accordingly). After both passes, rebuild
BulkInvitedUsersResult.results by iterating the original parsed_rows in order
and collecting results_by_row_number[row.row_number] so the final results list
preserves the input row order; use the same types (BulkInvitedUserRowResult) and
the existing symbols (parsed_rows, valid_rows, _BULK_INVITE_BATCH_SIZE,
create_invited_user, mask_email) when implementing.
---
Nitpick comments:
In `@autogpt_platform/backend/backend/data/invited_user.py`:
- Line 48: The hardcoded _BULK_INVITE_BATCH_SIZE should be made configurable by
reading from an environment/config variable (e.g.,
os.getenv("BULK_INVITE_BATCH_SIZE")) with a fallback default of 500; locate the
_BULK_INVITE_BATCH_SIZE constant in invited_user.py and replace its literal with
code that reads the env var, casts to int, validates/clamps to a sensible >0
value, and uses the default if parsing fails, and update any related tests or
docs to note the new BULK_INVITE_BATCH_SIZE config option.
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: c8ddee36-59f1-481d-a1b4-b8912ddd54bd
📒 Files selected for processing (2)
autogpt_platform/backend/backend/data/invited_user.pyautogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
✅ Files skipped from review due to trivial changes (1)
- autogpt_platform/frontend/src/app/(platform)/admin/users/components/BulkInviteForm/BulkInviteForm.tsx
📜 Review details
⏰ Context from checks skipped due to timeout of 90000ms. You can increase the timeout in your CodeRabbit configuration to a maximum of 15 minutes (900000ms). (6)
- GitHub Check: check API types
- GitHub Check: end-to-end tests
- GitHub Check: test (3.11)
- GitHub Check: test (3.13)
- GitHub Check: test (3.12)
- GitHub Check: Check PR Status
🧰 Additional context used
📓 Path-based instructions (6)
autogpt_platform/backend/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/backend/**/*.py: Use Python 3.11 (required; managed by Poetry via pyproject.toml) for backend development
Always run 'poetry run format' (Black + isort) before linting in backend development
Always run 'poetry run lint' (ruff) after formatting in backend development
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/backend/backend/data/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
All data access in backend requires user ID checks; verify this for any 'data/*.py' changes
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/backend/**/*.{py,txt}
📄 CodeRabbit inference engine (autogpt_platform/backend/CLAUDE.md)
Use
poetry runprefix for all Python commands, including testing, linting, formatting, and migrations
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/backend/backend/**/*.py
📄 CodeRabbit inference engine (autogpt_platform/backend/CLAUDE.md)
Use Prisma ORM for database operations in PostgreSQL with pgvector for embeddings
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/**/*.py
📄 CodeRabbit inference engine (AGENTS.md)
Format Python code with
poetry run format
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/**/data/*.py
📄 CodeRabbit inference engine (AGENTS.md)
For changes touching
data/*.py, validate user ID checks or explain why not needed
Files:
autogpt_platform/backend/backend/data/invited_user.py
🧠 Learnings (5)
📓 Common learnings
Learnt from: Swiftyos
Repo: Significant-Gravitas/AutoGPT PR: 12347
File: autogpt_platform/backend/backend/data/invited_user.py:193-193
Timestamp: 2026-03-10T11:22:18.867Z
Learning: In Significant-Gravitas/AutoGPT, the admin data-layer functions in `autogpt_platform/backend/backend/data/invited_user.py` (`list_invited_users`, `create_invited_user`, `revoke_invited_user`, `retry_invited_user_tally`, `bulk_create_invited_users_from_file`) intentionally omit an acting-user/admin ID parameter. Authorization for these functions is enforced entirely at the FastAPI router layer via `Security(requires_admin_user)` in `user_admin_routes.py`. Do not flag the absence of a user_id/actor_id parameter in these functions as a missing data-access guardrail violation.
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12284
File: autogpt_platform/frontend/src/app/api/openapi.json:11897-11900
Timestamp: 2026-03-04T23:58:18.476Z
Learning: Repo: Significant-Gravitas/AutoGPT — PR `#12284`
Backend/frontend OpenAPI codegen convention: In backend/api/features/store/model.py, the StoreSubmission and StoreSubmissionAdminView models define submitted_at: datetime | None, changes_summary: str | None, and instructions: str | None with no default. This is intentional to produce “required but nullable” fields in OpenAPI (properties appear in required[] and use anyOf [type, null]). This matches Prisma’s submittedAt DateTime? and changesSummary String?. Do not flag this as a required/nullable mismatch.
📚 Learning: 2026-03-10T11:22:14.861Z
Learnt from: Swiftyos
Repo: Significant-Gravitas/AutoGPT PR: 12347
File: autogpt_platform/backend/backend/data/invited_user.py:193-193
Timestamp: 2026-03-10T11:22:14.861Z
Learning: In autogpt_platform/backend/backend/data/invited_user.py, the admin data-layer functions (list_invited_users, create_invited_user, revoke_invited_user, retry_invited_user_tally, bulk_create_invited_users_from_file) intentionally omit an acting-user/admin ID parameter. Authorization is enforced exclusively at the FastAPI router layer via Security(requires_admin_user) in user_admin_routes.py. Do not flag the absence of a user_id/actor_id parameter in these functions as a missing data-access guardrail violation; rely on the router-level authorization. When reviewing related code, verify that any function that bypasses a parameter for performance or separation of concerns is complemented by equivalent security checks at the boundary (router) and that tests cover that authorization path in the router rather than in the data layer.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
📚 Learning: 2026-02-26T17:02:22.448Z
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12211
File: .pre-commit-config.yaml:160-179
Timestamp: 2026-02-26T17:02:22.448Z
Learning: Keep the pre-commit hook pattern broad for autogpt_platform/backend to ensure OpenAPI schema changes are captured. Do not narrow to backend/api/ alone, since the generated schema depends on Pydantic models across multiple directories (backend/data/, backend/blocks/, backend/copilot/, backend/integrations/, backend/util/). Narrowing could miss schema changes and cause frontend type desynchronization.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
📚 Learning: 2026-03-05T15:42:08.207Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12297
File: .claude/skills/backend-check/SKILL.md:14-16
Timestamp: 2026-03-05T15:42:08.207Z
Learning: In Python files under autogpt_platform/backend (recursively), rely on poetry run format to perform formatting (Black + isort) and linting (ruff). Do not run poetry run lint as a separate step after poetry run format, since format already includes linting checks.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
📚 Learning: 2026-03-16T16:35:40.236Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12440
File: autogpt_platform/backend/backend/api/features/workflow_import.py:54-63
Timestamp: 2026-03-16T16:35:40.236Z
Learning: Avoid using the word 'competitor' in public-facing identifiers and text. Use neutral naming for API paths, model names, function names, and UI text. Examples: rename 'CompetitorFormat' to 'SourcePlatform', 'convert_competitor_workflow' to 'convert_workflow', '/competitor-workflow' to '/workflow'. Apply this guideline to files under autogpt_platform/backend and autogpt_platform/frontend.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
🔇 Additional comments (1)
autogpt_platform/backend/backend/data/invited_user.py (1)
449-477: Good per-row failure handling and masked logging.Mapping
PreconditionFailedtoSKIPPEDand masking emails for unexpected failures keeps batch processing resilient while reducing sensitive data exposure in logs.
The two-pass approach (validate first, then batch-create) causes validation failures to appear before creation results in the list. Sort by row_number so results always match input file order.
There was a problem hiding this comment.
🧹 Nitpick comments (1)
autogpt_platform/backend/backend/data/invited_user.py (1)
441-447: Consider a semaphore for finer-grained concurrency control.Each
create_invited_userissues 2-3 DB queries, so 500 concurrent calls could spike to 1000-1500 concurrent DB operations per batch. If the connection pool is smaller (e.g., 20-50 connections), this may cause contention.An optional enhancement is to wrap the gather with a semaphore:
_DB_CONCURRENCY = asyncio.Semaphore(50) async def _create_with_limit(email: str, name: str | None): async with _DB_CONCURRENCY: return await create_invited_user(email, name)This is optional since batching already bounds the total concurrent work per request and the current approach was the accepted solution from prior review.
🤖 Prompt for AI Agents
Verify each finding against the current code and only fix it if needed. In `@autogpt_platform/backend/backend/data/invited_user.py` around lines 441 - 447, The current batch loop uses asyncio.gather(*(create_invited_user(...))) which can still yield many simultaneous DB queries; introduce a module-level asyncio.Semaphore (e.g., _DB_CONCURRENCY = asyncio.Semaphore(50)) and a small wrapper coroutine (e.g., _create_with_limit(email, name)) that acquires the semaphore before calling create_invited_user and releases on exit, then replace the gather call to invoke _create_with_limit for each item in the batch instead of calling create_invited_user directly; keep the existing batching via _BULK_INVITE_BATCH_SIZE and return_exceptions=True.
🤖 Prompt for all review comments with AI agents
Verify each finding against the current code and only fix it if needed.
Nitpick comments:
In `@autogpt_platform/backend/backend/data/invited_user.py`:
- Around line 441-447: The current batch loop uses
asyncio.gather(*(create_invited_user(...))) which can still yield many
simultaneous DB queries; introduce a module-level asyncio.Semaphore (e.g.,
_DB_CONCURRENCY = asyncio.Semaphore(50)) and a small wrapper coroutine (e.g.,
_create_with_limit(email, name)) that acquires the semaphore before calling
create_invited_user and releases on exit, then replace the gather call to invoke
_create_with_limit for each item in the batch instead of calling
create_invited_user directly; keep the existing batching via
_BULK_INVITE_BATCH_SIZE and return_exceptions=True.
ℹ️ Review info
⚙️ Run configuration
Configuration used: Organization UI
Review profile: CHILL
Plan: Pro
Run ID: 7f60bd17-e742-47d9-b17d-791c7ca65ed7
📒 Files selected for processing (1)
autogpt_platform/backend/backend/data/invited_user.py
📜 Review details
⏰ Context from checks skipped due to timeout of 90000ms. You can increase the timeout in your CodeRabbit configuration to a maximum of 15 minutes (900000ms). (13)
- GitHub Check: check API types
- GitHub Check: integration_test
- GitHub Check: end-to-end tests
- GitHub Check: Seer Code Review
- GitHub Check: type-check (3.11)
- GitHub Check: test (3.12)
- GitHub Check: test (3.13)
- GitHub Check: test (3.11)
- GitHub Check: type-check (3.13)
- GitHub Check: Analyze (python)
- GitHub Check: type-check (3.12)
- GitHub Check: Check PR Status
- GitHub Check: conflicts
🧰 Additional context used
📓 Path-based instructions (6)
autogpt_platform/backend/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
autogpt_platform/backend/**/*.py: Use Python 3.11 (required; managed by Poetry via pyproject.toml) for backend development
Always run 'poetry run format' (Black + isort) before linting in backend development
Always run 'poetry run lint' (ruff) after formatting in backend development
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/backend/backend/data/**/*.py
📄 CodeRabbit inference engine (.github/copilot-instructions.md)
All data access in backend requires user ID checks; verify this for any 'data/*.py' changes
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/backend/**/*.{py,txt}
📄 CodeRabbit inference engine (autogpt_platform/backend/CLAUDE.md)
Use
poetry runprefix for all Python commands, including testing, linting, formatting, and migrations
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/backend/backend/**/*.py
📄 CodeRabbit inference engine (autogpt_platform/backend/CLAUDE.md)
Use Prisma ORM for database operations in PostgreSQL with pgvector for embeddings
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/**/*.py
📄 CodeRabbit inference engine (AGENTS.md)
Format Python code with
poetry run format
Files:
autogpt_platform/backend/backend/data/invited_user.py
autogpt_platform/**/data/*.py
📄 CodeRabbit inference engine (AGENTS.md)
For changes touching
data/*.py, validate user ID checks or explain why not needed
Files:
autogpt_platform/backend/backend/data/invited_user.py
🧠 Learnings (5)
📓 Common learnings
Learnt from: Swiftyos
Repo: Significant-Gravitas/AutoGPT PR: 12347
File: autogpt_platform/backend/backend/data/invited_user.py:193-193
Timestamp: 2026-03-10T11:22:18.867Z
Learning: In Significant-Gravitas/AutoGPT, the admin data-layer functions in `autogpt_platform/backend/backend/data/invited_user.py` (`list_invited_users`, `create_invited_user`, `revoke_invited_user`, `retry_invited_user_tally`, `bulk_create_invited_users_from_file`) intentionally omit an acting-user/admin ID parameter. Authorization for these functions is enforced entirely at the FastAPI router layer via `Security(requires_admin_user)` in `user_admin_routes.py`. Do not flag the absence of a user_id/actor_id parameter in these functions as a missing data-access guardrail violation.
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12284
File: autogpt_platform/frontend/src/app/api/openapi.json:11897-11900
Timestamp: 2026-03-04T23:58:18.476Z
Learning: Repo: Significant-Gravitas/AutoGPT — PR `#12284`
Backend/frontend OpenAPI codegen convention: In backend/api/features/store/model.py, the StoreSubmission and StoreSubmissionAdminView models define submitted_at: datetime | None, changes_summary: str | None, and instructions: str | None with no default. This is intentional to produce “required but nullable” fields in OpenAPI (properties appear in required[] and use anyOf [type, null]). This matches Prisma’s submittedAt DateTime? and changesSummary String?. Do not flag this as a required/nullable mismatch.
📚 Learning: 2026-03-10T11:22:14.861Z
Learnt from: Swiftyos
Repo: Significant-Gravitas/AutoGPT PR: 12347
File: autogpt_platform/backend/backend/data/invited_user.py:193-193
Timestamp: 2026-03-10T11:22:14.861Z
Learning: In autogpt_platform/backend/backend/data/invited_user.py, the admin data-layer functions (list_invited_users, create_invited_user, revoke_invited_user, retry_invited_user_tally, bulk_create_invited_users_from_file) intentionally omit an acting-user/admin ID parameter. Authorization is enforced exclusively at the FastAPI router layer via Security(requires_admin_user) in user_admin_routes.py. Do not flag the absence of a user_id/actor_id parameter in these functions as a missing data-access guardrail violation; rely on the router-level authorization. When reviewing related code, verify that any function that bypasses a parameter for performance or separation of concerns is complemented by equivalent security checks at the boundary (router) and that tests cover that authorization path in the router rather than in the data layer.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
📚 Learning: 2026-02-26T17:02:22.448Z
Learnt from: Pwuts
Repo: Significant-Gravitas/AutoGPT PR: 12211
File: .pre-commit-config.yaml:160-179
Timestamp: 2026-02-26T17:02:22.448Z
Learning: Keep the pre-commit hook pattern broad for autogpt_platform/backend to ensure OpenAPI schema changes are captured. Do not narrow to backend/api/ alone, since the generated schema depends on Pydantic models across multiple directories (backend/data/, backend/blocks/, backend/copilot/, backend/integrations/, backend/util/). Narrowing could miss schema changes and cause frontend type desynchronization.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
📚 Learning: 2026-03-05T15:42:08.207Z
Learnt from: ntindle
Repo: Significant-Gravitas/AutoGPT PR: 12297
File: .claude/skills/backend-check/SKILL.md:14-16
Timestamp: 2026-03-05T15:42:08.207Z
Learning: In Python files under autogpt_platform/backend (recursively), rely on poetry run format to perform formatting (Black + isort) and linting (ruff). Do not run poetry run lint as a separate step after poetry run format, since format already includes linting checks.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
📚 Learning: 2026-03-16T16:35:40.236Z
Learnt from: majdyz
Repo: Significant-Gravitas/AutoGPT PR: 12440
File: autogpt_platform/backend/backend/api/features/workflow_import.py:54-63
Timestamp: 2026-03-16T16:35:40.236Z
Learning: Avoid using the word 'competitor' in public-facing identifiers and text. Use neutral naming for API paths, model names, function names, and UI text. Examples: rename 'CompetitorFormat' to 'SourcePlatform', 'convert_competitor_workflow' to 'convert_workflow', '/competitor-workflow' to '/workflow'. Apply this guideline to files under autogpt_platform/backend and autogpt_platform/frontend.
Applied to files:
autogpt_platform/backend/backend/data/invited_user.py
🔇 Additional comments (3)
autogpt_platform/backend/backend/data/invited_user.py (3)
48-48: LGTM!The renamed constant
_BULK_INVITE_BATCH_SIZEwith underscore prefix correctly signals internal use, and 500 is a sensible batch size for bounding concurrent DB operations perasyncio.gathercall.
405-439: LGTM!The first pass efficiently validates email format and deduplicates entries before any DB operations. Collecting
(row, normalized_email, row_name)tuples preserves the original row number for accurate result reporting while avoiding redundant normalization in the second pass.
491-491: LGTM!Sorting by
row_numberensures results appear in input-file order despite the two-pass (validate-then-create) approach producing interleaved results.
…icant-Gravitas/AutoGPT into swiftyos/remove-bulk-invite-limit
autogpt_platform/backend/backend/api/features/admin/user_admin_routes.py
Show resolved
Hide resolved
 majdyz
left a comment
majdyz
left a comment
There was a problem hiding this comment.
Review summary
Verdict: 🚫 Request Changes — 1 blocker, 4 should-fixes need addressing before merge.
🔴 Blocker (1)
isinstance(outcome, BaseException)in_create_bulk_invite_resultsswallowsKeyboardInterrupt/SystemExit— change toisinstance(outcome, Exception)
🟠 Should Fix (4)
response is None/RuntimeErrorinextract_business_understanding_from_tallyis unreachable dead code — useassertor remove the sentinelTallyExtractionTimeoutError(asyncio.TimeoutError)will be accidentally caught byexcept asyncio.TimeoutError/except OSError— inherit fromExceptioninstead- For 5,000-row bulk uploads, 5,000 background Tally tasks are all scheduled immediately without backpressure — see inline comment for approach
asyncio.sleep(_TALLY_RATE_DELAY)fires even for users with no Tally submission, making O(n × 0.6s) unavoidable even for empty results
🟡 Nice to Have (2)
where: dict = {}should be typed asprisma.types.InvitedUserWhereInputsearch: str = Query("")should beOptional[str] = Query(None)for clean API semantics
The overall structure of this PR is solid — the batch precheck, modular helpers, retry/backoff on Tally, and test coverage are all good work. The blocker and should-fixes are all small, targeted changes.
…andler Re-raises system-level exceptions (KeyboardInterrupt, SystemExit, etc.) from asyncio.gather(return_exceptions=True) instead of silently swallowing them as error results. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
- Change TallyExtractionTimeoutError to inherit from Exception instead of asyncio.TimeoutError to prevent silent catch by upstream except OSError or except asyncio.TimeoutError handlers. - Replace unreachable `response is None` RuntimeError with assert. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
Remove _build_bulk_invited_user_row_result helper that wrapped BulkInvitedUserRowResult with positional args. Use named kwargs directly for readability at each call site. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
Use prisma.types.InvitedUserWhereInput and InvitedUserUpdateInput instead of untyped dict for schema-aware query construction. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
Only sleep after successful Tally API lookups. For bulk imports where most users have no Tally record, this avoids burning 0.6s per 404. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
…d task Instead of spawning up to 5,000 independent background tasks via schedule_invited_user_tally_precompute, bulk uploads now skip per-row scheduling and instead launch a single task that processes enrichment serially. This bounds event-loop pressure and respects the existing semaphores and rate limits. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
Move public API functions (get_or_activate_user, check_invite_eligibility, list_invited_users, create_invited_user, etc.) before their private helpers so readers encounter high-level logic first. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
…iftyos/remove-bulk-invite-limit
Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
Update test_bulk_create_invited_users_limits_create_concurrency to accept the new schedule_tally kwarg and mock _schedule_bulk_tally_enrichment. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
The assertion on fetch_sleep.await_count was racing with the 4th task's sleep call. Python 3.12+ changed asyncio event loop scheduling, causing the 4th task's sleep to not have completed when three_extractions_started fires. Move the assertion after await asyncio.gather(*tasks) to make it deterministic across Python versions. Co-Authored-By: Claude Opus 4.6 (1M context) <noreply@anthropic.com>
There was a problem hiding this comment.
All 8 specialist reports are in. Now compiling the final verdict.
PR #12471 — feat(platform): improve invited user admin workflows
Author: Swiftyos (Swifty) | Requested by: Review Squad | Files: 313 changed (+38,958 / -4,001)
Key files: invited_user.py (+/-), tally.py (+/-), user_admin_routes.py (+), model.py (+/-), InvitedUsersTable.tsx (+/-), useAdminUsersPage.ts (+/-), BulkInviteForm.tsx (+/-), openapi.json (+/-)
🎯 Verdict: REQUEST_CHANGES
What This PR Does
Scales the admin invited-user workflow from a 500-user manual ceiling to a 5,000-user bulk pipeline. Bulk uploads now validate and deduplicate rows before batch creation, return per-row CREATED/SKIPPED/ERROR results, and run Tally form enrichment in a rate-limited background pipeline. The admin UI gains server-side search with debounced input and Previous/Next pagination. Tally LLM extraction gets retry logic with exponential backoff and a dedicated timeout error type.
Specialist Findings
🛡️ Security ✅ — All admin endpoints properly gated with Security(requires_admin_user) at router level. Search parameter uses Prisma's parameterized contains — no SQL injection risk. Email enumeration via _fetch_existing_emails is acceptable given admin-only access. The TOCTOU race in create_invited_user (check-then-create) is mitigated by UniqueViolationError catch. Minor: no max_length on the search query param, tally_understanding dict exposed in list responses, and no backend-side file-size validation for bulk upload (only client-side 1MB check).
🏗️ Architecture
invited_user.py at ~1,087 lines is 3.5× the project's own 300-line guideline — mixes CRUD, activation logic, bulk pipeline, and Tally orchestration. Should split into 3 modules.
asyncio.Semaphore(1) and Semaphore(3)) don't work across multiple uvicorn workers — effective concurrency to Tally API becomes N_workers × cap, not the intended cap. The AsyncClusterLock handles idempotency but not rate limiting.
_tally_seed_tasks is process-local mutable state — fire-and-forget tasks lost on restart with no persistent job queue.
⚡ Performance
name column (invited_user.py:236-241): ILIKE '%search%' on name forces sequential scan. The email unique index also can't help due to leading wildcard. Need trigram GIN index for scale past ~5K rows.
_bulk_create_invited_user bypassing redundant checks.
_tally_lookup_semaphore = Semaphore(1) serializes all lookups globally.
_fetch_existing_emails chunks: 10 serial iterations for 5,000 emails could be parallelized.
🧪 Testing
revoke_invited_user on CLAIMED user, retry_invited_user_tally on REVOKED user
InvitedUsersTable, useAdminUsersPage
📖 Quality
create_invited_user, revoke_invited_user, list_invited_users lack docstrings entirely.
_EmailValidatedInviteRow = tuple[...] should be a NamedTuple for self-documenting field access.
Semaphore(1) should be asyncio.Lock() to communicate intent (functionally identical).
debug log statements use f-strings instead of deferred %s interpolation per project style guide (tally.py:473).
📦 Product ✅ — All claimed features implemented and verified. UX is clear with per-row results, debounced search, and proper loading states.
InvitedUsersTable.tsx:166).
InvitedUsersTable.tsx:232).
📬 Discussion ✅ — Extensive review history: 50+ inline comments across @majdyz (CHANGES_REQUESTED), @Pwuts, @coderabbitai, and @sentry[bot]. All critical/blocker issues from previous rounds have been addressed:
BaseExceptionswallowing → fixed (re-raises system exceptions)TallyExtractionTimeoutErrorwrong base class → fixed (inheritsException)- Undefined
_BULK_INVITE_BATCH_SIZE→ fixed (replaced with semaphore) - 5,000 background tasks → fixed (serial background enrichment)
- Prisma type safety → fixed (
InvitedUserWhereInput/InvitedUserUpdateInput) - File ordering → fixed (full reorder)
Remaining unaddressed: author's own self-review suggestions (NamedTuple, parallel chunk fetch), @majdyz'sQuery("")→Optional[str]suggestion (resolved as won't-fix).
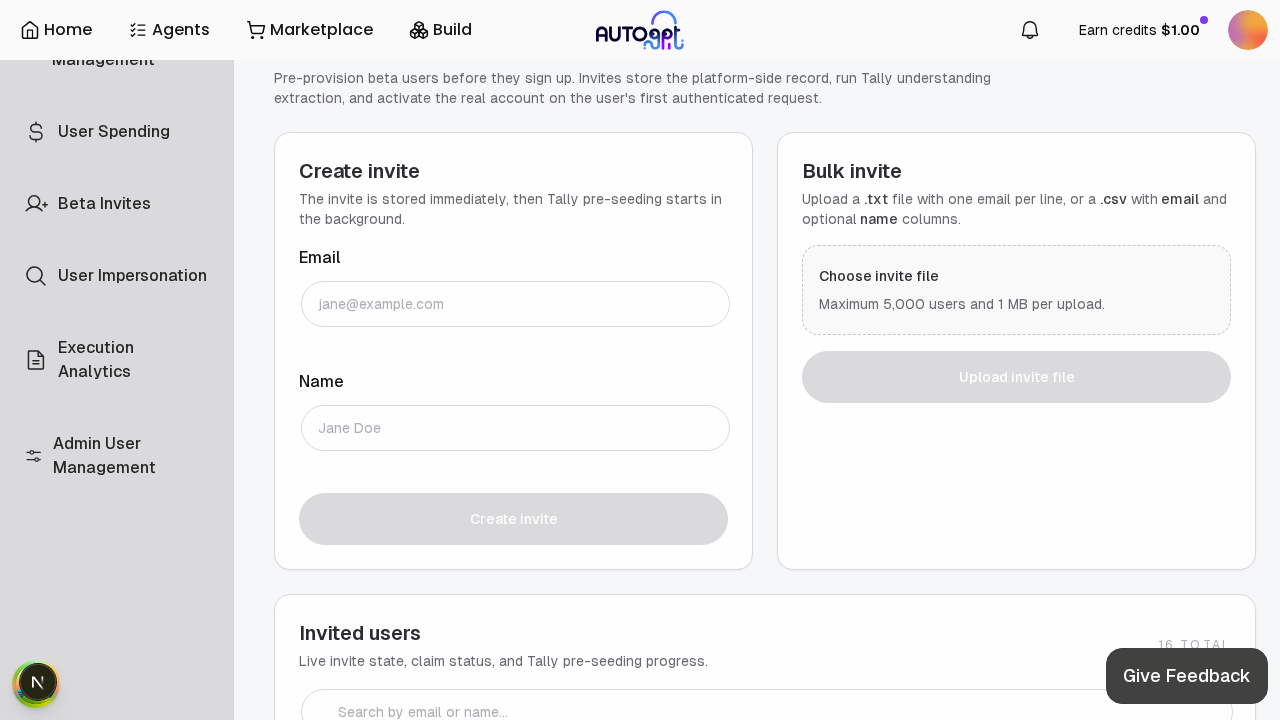
🔎 QA ✅ — Full live testing completed with screenshots. All features verified end-to-end:
- Search filters correctly with live count update
- Pagination controls render (hidden when ≤1 page, shown with smaller page_size)
- Create invite form works: submit → table refresh → new user at top
- Bulk invite label shows "Maximum 5,000 users and 1 MB per upload"
- Admin gating verified (403 for non-admin)
- Tally status displays correctly (FAILED with expected "API key not configured" in test env)
Blockers (Must Fix)
None — all previous blockers from @majdyz's review have been addressed.
Should Fix (Follow-up OK)
invited_user.py— split into 3 modules (1,087 lines, 3.5× guideline). Bulk pipeline + Tally orchestration + CRUD should be separate files.invited_user.py:236-241— add database index for search:namecolumn is unindexed;ILIKE '%term%'on bothemailandnamewill degrade at scale. Add trigram GIN index or at minimum@@index([name]).invited_user.py:262-292— deduplicate DB queries in bulk create: Pre-check already fetches existing emails, but eachcreate_invited_usercall re-checks. A dedicated_bulk_create_invited_userwould cut ~10,000 redundant queries for a 5,000-row upload.InvitedUsersTable.tsx:166— fix empty search state message: Currently shows "No invited users yet" when search returns 0 — should say "No matching invited users".InvitedUsersTable.tsx:232— add confirmation dialog for Revoke: Destructive action with no confirmation.- Docstring coverage (17% → 80%): Add docstrings to all public functions in
invited_user.py,user_admin_routes.py. - Frontend test coverage: Add tests for
InvitedUsersTable(search, pagination) anduseAdminUsersPagehook. invited_user.py:49— process-local semaphores: Note in code that these only work per-process and won't cap cross-worker concurrency. Consider documenting single-worker assumption or using Redis-based rate limiting.
Risk Assessment
Merge risk: MEDIUM | Rollback: EASY
The core changes are admin-only and additive — no existing user-facing flows are modified. Bulk invite scaling is safe (pre-check + unique constraint guard). Main risk is the serial Tally enrichment taking very long for large uploads (~50+ min for 5K users), but this runs in background and doesn't block the request. The merge conflict with #12407 on invited_user.py needs coordination.
REVIEW_COMPLETE
PR: #12471
Verdict: REQUEST_CHANGES
Blockers: 0
## Summary Reverts the invite system PRs due to security gaps identified during review: - The move from Supabase-native `allowed_users` gating to application-level gating allows orphaned Supabase auth accounts (valid JWT without a platform `User`) - The auth middleware never verifies `User` existence, so orphaned users get 500s instead of clean 403s - OAuth/Google SSO signup completely bypasses the invite gate - The DB trigger that atomically created `User` + `Profile` on signup was dropped in favor of a client-initiated API call, introducing a failure window ### Reverted PRs - Reverts #12347 — Foundation: InvitedUser model, invite-gated signup, admin UI - Reverts #12374 — Tally enrichment: personalized prompts from form submissions - Reverts #12451 — Pre-check: POST /auth/check-invite endpoint - Reverts #12452 (collateral) — Themed prompt categories / SuggestionThemes UI. This PR built on top of #12374's `suggested_prompts` backend field and `/chat/suggested-prompts` endpoint, so it cannot remain without #12374. The copilot empty session falls back to hardcoded default prompts. ### Migration Includes a new migration (`20260319120000_revert_invite_system`) that: - Drops the `InvitedUser` table and its enums (`InvitedUserStatus`, `TallyComputationStatus`) - Restores the `add_user_and_profile_to_platform()` trigger on `auth.users` - Backfills `User` + `Profile` rows for any auth accounts created during the invite-gate window ### What's NOT reverted - The `generate_username()` function (never dropped, still used by backfill migration) - The old `add_user_to_platform()` function (superseded by `add_user_and_profile_to_platform()`) - PR #12471 (admin UX improvements) — was never merged, no action needed ## Test plan - [x] Verify migration: `InvitedUser` table dropped, enums dropped, trigger restored - [x] Verify backfill: no orphaned auth users, no users without Profile - [x] Verify existing users can still log in (email + OAuth) - [x] Verify CoPilot chat page loads with default prompts - [ ] Verify new user signup creates `User` + `Profile` via the restored trigger - [ ] Verify admin `/admin/users` page loads without crashing - [ ] Run backend tests: `poetry run test` 🤖 Generated with [Claude Code](https://claude.com/claude-code) --------- Co-authored-by: Claude Opus 4.6 (1M context) <noreply@anthropic.com> Co-authored-by: Zamil Majdy <zamil.majdy@agpt.co>
|
This pull request has conflicts with the base branch, please resolve those so we can evaluate the pull request. |
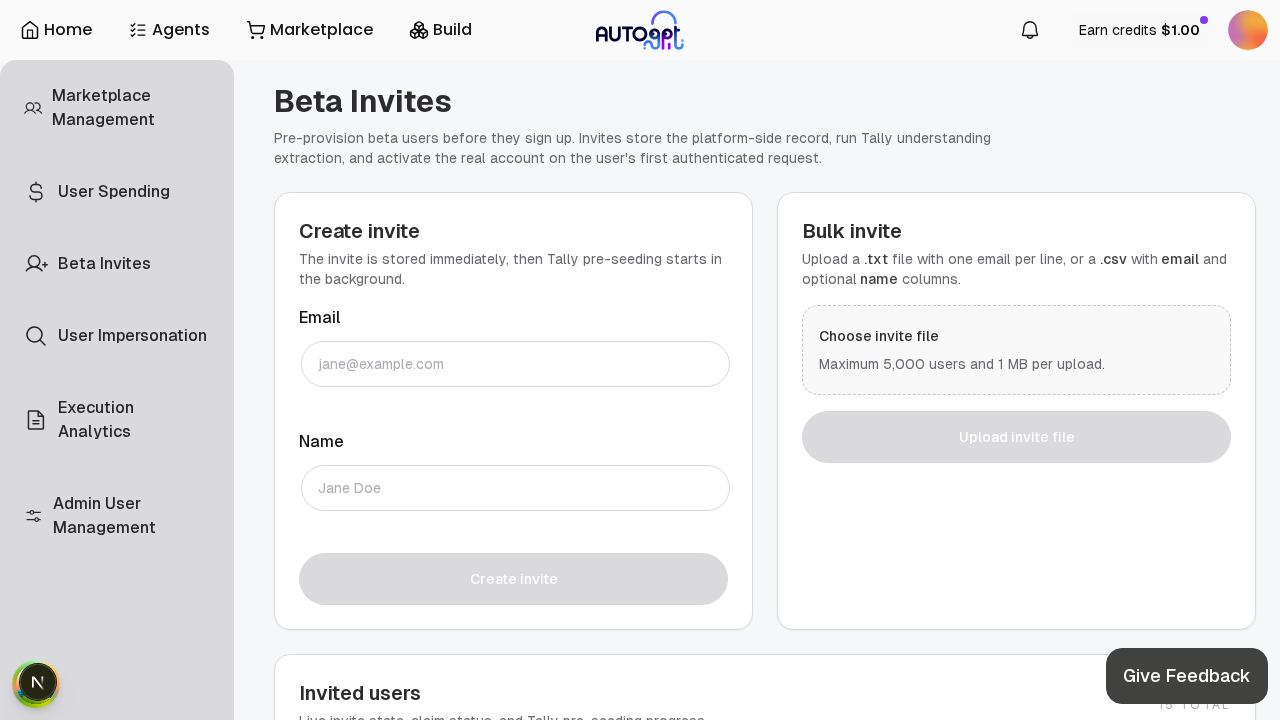
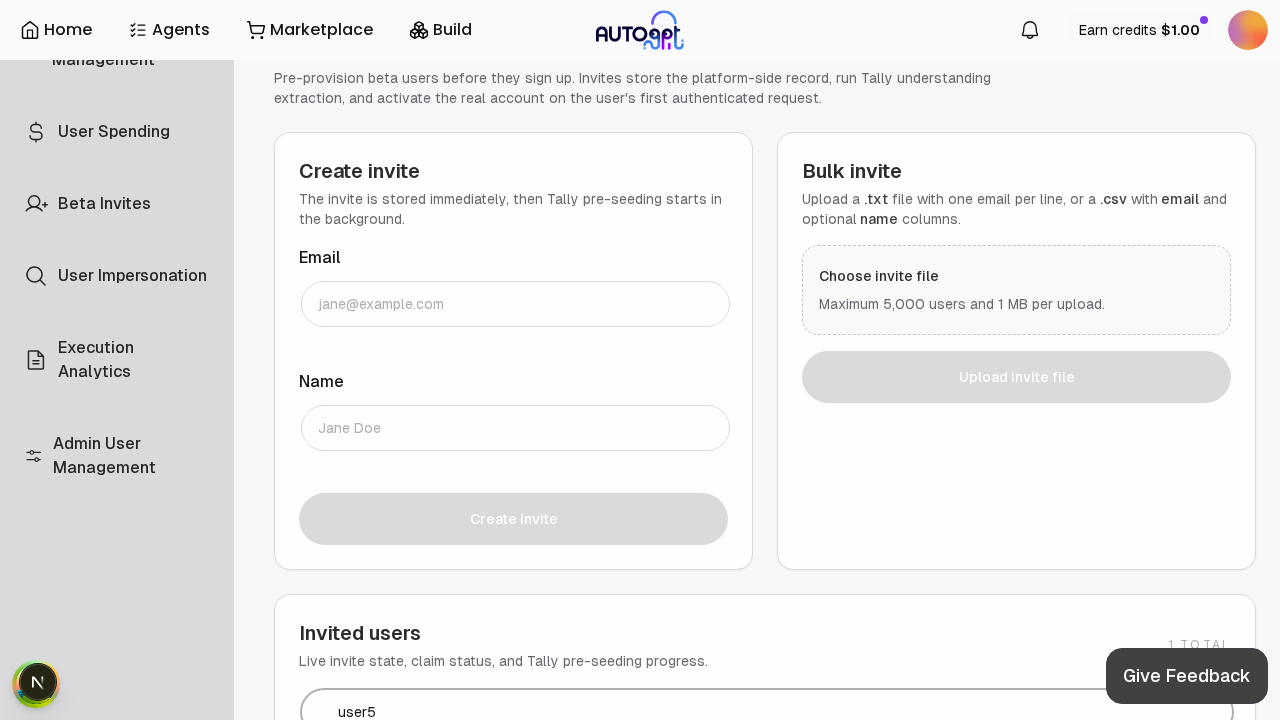
This expands the invited-user admin flow so bulk uploads scale better, invited-user lookup is searchable, and Tally enrichment behaves more gracefully under slow LLM responses.
Changes 🏗️
Checklist 📋
For code changes:
poetry run pytest backend/api/features/admin/user_admin_routes_test.py backend/data/invited_user_test.py backend/data/tally_test.pyPATH="$HOME/.nvm/versions/node/v22.21.1/bin:$PATH" pnpm generate:apiPATH="$HOME/.nvm/versions/node/v22.21.1/bin:$PATH" pnpm lintPATH="$HOME/.nvm/versions/node/v22.21.1/bin:$PATH" pnpm typesFor configuration changes:
.env.defaultis updated or already compatible with my changesdocker-compose.ymlis updated or already compatible with my changes